`generateBedReport`, `generateAmpliconReport`, `generateCaptureReport` – these functions match BAM reads to the set of genomic locations and return the fraction of reads with an average methylation level passing certain threshold.
Usage
generateAmpliconReport(
bam,
bed,
report.file = NULL,
zero.based.bed = FALSE,
match.tolerance = 1,
cytosine.context = c("CG", "CHG", "CHH", "CxG", "CX"),
filter.reads = TRUE,
min.context.sites = 0,
max.outofcontext.beta = 0.1,
threshold.reads = TRUE,
min.context.beta = 0.5,
...,
gzip = FALSE,
verbose = TRUE
)
generateCaptureReport(
bam,
bed,
report.file = NULL,
zero.based.bed = FALSE,
match.min.overlap = 1,
cytosine.context = c("CG", "CHG", "CHH", "CxG", "CX"),
filter.reads = TRUE,
min.context.sites = 0,
max.outofcontext.beta = 0.1,
threshold.reads = TRUE,
min.context.beta = 0.5,
...,
gzip = FALSE,
verbose = TRUE
)
generateBedReport(
bam,
bed,
report.file = NULL,
zero.based.bed = FALSE,
bed.type = c("amplicon", "capture"),
match.tolerance = 1,
match.min.overlap = 1,
cytosine.context = c("CG", "CHG", "CHH", "CxG", "CX"),
filter.reads = TRUE,
min.context.sites = 0,
max.outofcontext.beta = 0.1,
threshold.reads = TRUE,
min.context.beta = 0.5,
...,
gzip = FALSE,
verbose = TRUE
)Arguments
- bam
BAM file location string OR preprocessed output of
preprocessBamfunction. Read more about BAM file requirements and BAM preprocessing atpreprocessBam.- bed
Browser Extensible Data (BED) file location string OR object of class
GRangesholding genomic coordinates for regions of interest. The style of seqlevels of BED file/object must be the same as the style of seqlevels of BAM file/object used. The BED/GRangesrows are not sorted internally. As of now, the strand information is ignored and reads (read pairs) matching both strands are separately counted and reported.- report.file
file location string to write the BED report. If NULL (the default) then report is returned as a
data.tableobject.- zero.based.bed
boolean defining if BED coordinates are zero-based (default: FALSE).
- match.tolerance
integer for the largest difference between read's and BED
GRangesstart or end positions during matching of amplicon-based NGS reads (default: 1).- cytosine.context
string defining cytosine methylation context used for filtering and/or thresholding the reads:
"CG" (the default) – within-the-context: CpG cytosines (called as zZ), out-of-context: all the other cytosines (hHxX)
"CHG" – within-the-context: CHG cytosines (xX), out-of-context: hHzZ
"CHH" – within-the-context: CHH cytosines (hH), out-of-context: xXzZ
"CxG" – within-the-context: CG and CHG cytosines (zZxX), out-of-context: CHH cytosines (hH)
"CX" – all cytosines are considered within-the-context, this effectively results in no thresholding
- filter.reads
boolean defining if sequence reads with too few context bases or too high out-of-context cytosine methylation should be filtered out (e.g., reads resulting from incompletely bisulfite-converted templates). Default: TRUE. Filtering is strongly recommended for short-read sequencing (bisulfite or enzymatic) because it removes reads from incompletely converted DNA molecules.
- min.context.sites
non-negative integer for minimum number of cytosines within the `cytosine.context` (default: 0, i.e., all reads will satisfy this criterion). When `min.context.sites`>0, reads containing fewer within-the-context cytosines will not be thresholded and will be ignored in further computations. This option has no effect when read filtering is disabled.
- max.outofcontext.beta
real number in the range [0;1] (default: 0.1). Reads with average beta value for out-of-context cytosines above this threshold will not be thresholded and will be ignored in further computations. This option has no effect when read filtering is disabled.
- threshold.reads
boolean defining if sequence reads should be thresholded before counting reads belonging to variant epialleles (default: TRUE). Disabling thresholding is possible but makes no sense in the context of this function, because all the reads will be assigned to the variant epiallele, which will result in VEF==1 (in such case `NA` VEF values are returned in order to avoid confusion).
- min.context.beta
real number in the range [0;1] (default: 0.5). Reads with average beta value for within-the-context cytosines below this threshold are considered completely unmethylated (thus belonging to the reference epiallele). This option has no effect when read thresholding is disabled.
- ...
other parameters to pass to the
preprocessBamfunction. Options have no effect if preprocessed BAM data was supplied as an input.- gzip
boolean to compress the report (default: FALSE).
- verbose
boolean to report progress and timings (default: TRUE).
- match.min.overlap
integer for the smallest overlap between read's and BED
GRangesstart or end positions during matching of capture-based NGS reads (default: 1). If read matches two or more BED genomic regions, only the first match is taken (inputGRangesare not sorted internally).- bed.type
character string for the type of assay that was used to produce sequencing reads:
"amplicon" (the default) – used for amplicon-based next-generation sequencing when exact coordinates of sequenced fragments are known. Matching of reads to genomic ranges are then performed by the read's start or end positions, either of which should be no further than `match.tolerance` bases away from the start or end position of genomic ranges given in BED file/
GRangesobject"capture" – used for capture-based next-generation sequencing when reads partially overlap with the capture target regions. Read is considered to match the genomic range when their overlap is more or equal to `match.min.overlap`. If read matches two or more BED genomic regions, only the first match is taken (input
GRangesare not sorted internally)
Value
data.table object containing VEF report for
BED GRanges or NULL if report.file was
specified. If BAM file contains reads that would not match to any of BED
GRanges, the last row in the report will
contain information on such reads (with seqnames, start and end equal to NA).
The report columns are:
seqnames – reference sequence name
start – start of genomic region
end – end of genomic region
width – width of genomic region
strand – strand
... – other columns that were present in BED or metadata columns of
GRangesobjectnreads+ – number of valid reads (pairs) mapped to the forward ("+") strand
nreads- – number of valid reads (pairs) mapped to the reverse ("-") strand
nfiltered – number of invalid reads (pairs) filtered out due to too few context bases or too high out-of-context cytosine methylation (`NA` if filtering was disabled)
VEF – fraction of valid reads passing the threshold (`NA` if thresholding was disabled)
Details
Functions report hypermethylated variant epiallele frequencies (VEF) per genomic region of interest using BAM and BED files as input. Reads (for paired-end sequencing alignment files - read pairs as a single entity) are matched to genomic locations by exact coordinates (`generateAmpliconReport` or `generateBedReport` with an option bed.type="amplicon") or minimum overlap (`generateCaptureReport` or `generateBedReport` with an option bed.type="capture") – the former to be used for amplicon-based NGS data, while the latter – for the capture-based NGS data. The function's logic is explained below.
NB: you can modify and/or run this example – see Examples section at the bottom of this page.
Suppose there is a BAM file with four reads, all mapped to the "+" strand of chromosome 1, positions 1-16. The genomic range is supplied as a parameter `bed = as("chr1:1-100", "GRanges")`. Assuming the following values for the filtering and thresholding parameters (cytosine.context = "CG", filter.reads = TRUE, min.context.sites = 2, max.outofcontext.beta = 0.1, threshold.reads = TRUE, min.context.beta = 0.5), the input and the output results will look as follows:
| methylation string | filter | threshold | explained |
| ...Z..x+.h..x..h. | excluded | <NA> | min.context.sites < 2 (only one zZ base) |
| ...Z..z.h..x..h. | pass | above | pass all criteria |
| ...Z..z.h..X..h. | excluded | <NA> | max.outofcontext.beta > 0.1 (1XH / 3xXhH = 0.33) |
| ...Z..z.h..z-.h. | pass | below | min.context.beta < 0.5 (1Z / 3zZ = 0.33) |
Since the reads number one and three are filtered out, and only the second read will satisfy the thresholding criteria, the following BED report will be produced (again, given that all reads map to chr1:+:1-16):
| seqnames | start | end | width | strand | nreads+ | nreads- | nfiltered | VEF |
| chr1 | 1 | 100 | 100 | * | 2 | 0 | 2 | 0.5 |
Please note, that read thresholding by an average methylation level
(as explained above) makes little sense for long-read sequencing alignments,
as such reads can cover multiple regions with very different DNA methylation
properties. If necessary, one could either clip long sequencing reads to
narrow `targets` in preprocessBam function during BAM loading
or use extractPatterns, limiting
pattern output to the region of interest only.
See also
preprocessBam for preloading BAM data,
generateCytosineReport for methylation statistics at the level
of individual cytosines, generateVcfReport for evaluating
epiallele-SNV associations, extractPatterns for exploring
methylation patterns and plotPatterns for pretty plotting
of its output, generateBedEcdf for analysing the
distribution of per-read beta values, and `epialleleR` vignettes for the
description of usage and sample data.
GRanges class for working with genomic ranges,
seqlevelsStyle function for getting or setting
the seqlevels style.
Examples
# amplicon data
amplicon.bam <- system.file("extdata", "amplicon010meth.bam",
package="epialleleR")
amplicon.bed <- system.file("extdata", "amplicon.bed",
package="epialleleR")
amplicon.report <- generateAmpliconReport(bam=amplicon.bam,
bed=amplicon.bed)
#> Reading BED file
#> [0.007s]
#> Checking BAM file:
#> short-read, paired-end, name-sorted alignment detected
#> Reading paired-end BAM file
#> [0.004s]
#> Filtering and thresholding reads
#> [0.000s]
#> Preparing amplicon report
#> [0.013s]
plotPatterns(
extractPatterns(
bam=amplicon.bam, bed=amplicon.bed, match.min.overlap=100
), npatterns.per.bin=Inf
)
#> Reading BED file
#> [0.007s]
#> Checking BAM file:
#> short-read, paired-end, name-sorted alignment detected
#> Reading paired-end BAM file
#> [0.003s]
#> Extracting methylation patterns
#> [0.011s]
#> 156 patterns supplied
#> 10 unique
#> 10 most frequent unique patterns were selected for plotting using 10 beta value bins:
#> [0,0.1) [0.1,0.2) [0.2,0.3) [0.3,0.4) [0.4,0.5) [0.5,0.6) [0.6,0.7) [0.7,0.8) [0.8,0.9) [0.9,1]
#> 6 0 0 0 1 0 0 0 1 2
 # capture NGS
capture.bam <- system.file("extdata", "capture.bam",
package="epialleleR")
capture.bed <- system.file("extdata", "capture.bed",
package="epialleleR")
capture.report <- generateCaptureReport(bam=capture.bam, bed=capture.bed)
#> Reading BED file
#> [0.008s]
#> Checking BAM file:
#> short-read, paired-end, name-sorted alignment detected
#> Reading paired-end BAM file
#> [0.011s]
#> Filtering and thresholding reads
#> [0.001s]
#> Preparing capture report
#> [0.017s]
# generateAmpliconReport and generateCaptureReport are just aliases
# of the generateBedReport
bed.report <- generateBedReport(bam=capture.bam, bed=capture.bed,
bed.type="capture")
#> Reading BED file
#> [0.008s]
#> Checking BAM file:
#> short-read, paired-end, name-sorted alignment detected
#> Reading paired-end BAM file
#> [0.011s]
#> Filtering and thresholding reads
#> [0.001s]
#> Preparing capture report
#> [0.016s]
identical(capture.report, bed.report)
#> [1] TRUE
# long-read data can be used if clipped to a narrow target area(s)
long.bam <- system.file("extdata", "longread.bam", package="epialleleR")
long.bed <- as("chr17:43124909-43125554", "GRanges")
long.data <- preprocessBam(
bam=long.bam, targets=long.bed, clip.to.targets=TRUE,
min.mapq=30, min.baseq=20, min.prob=178
)
#> Checking BAM file:
#> long-read, single-end, unsorted alignment detected
#> Reading single-end BAM file
#> [0.007s]
long.report <- generateBedReport(
bam=long.data, bed=long.bed, bed.type="capture", filter.reads=FALSE
)
#> Thresholding reads
#> [0.001s]
#> Preparing capture report
#> [0.013s]
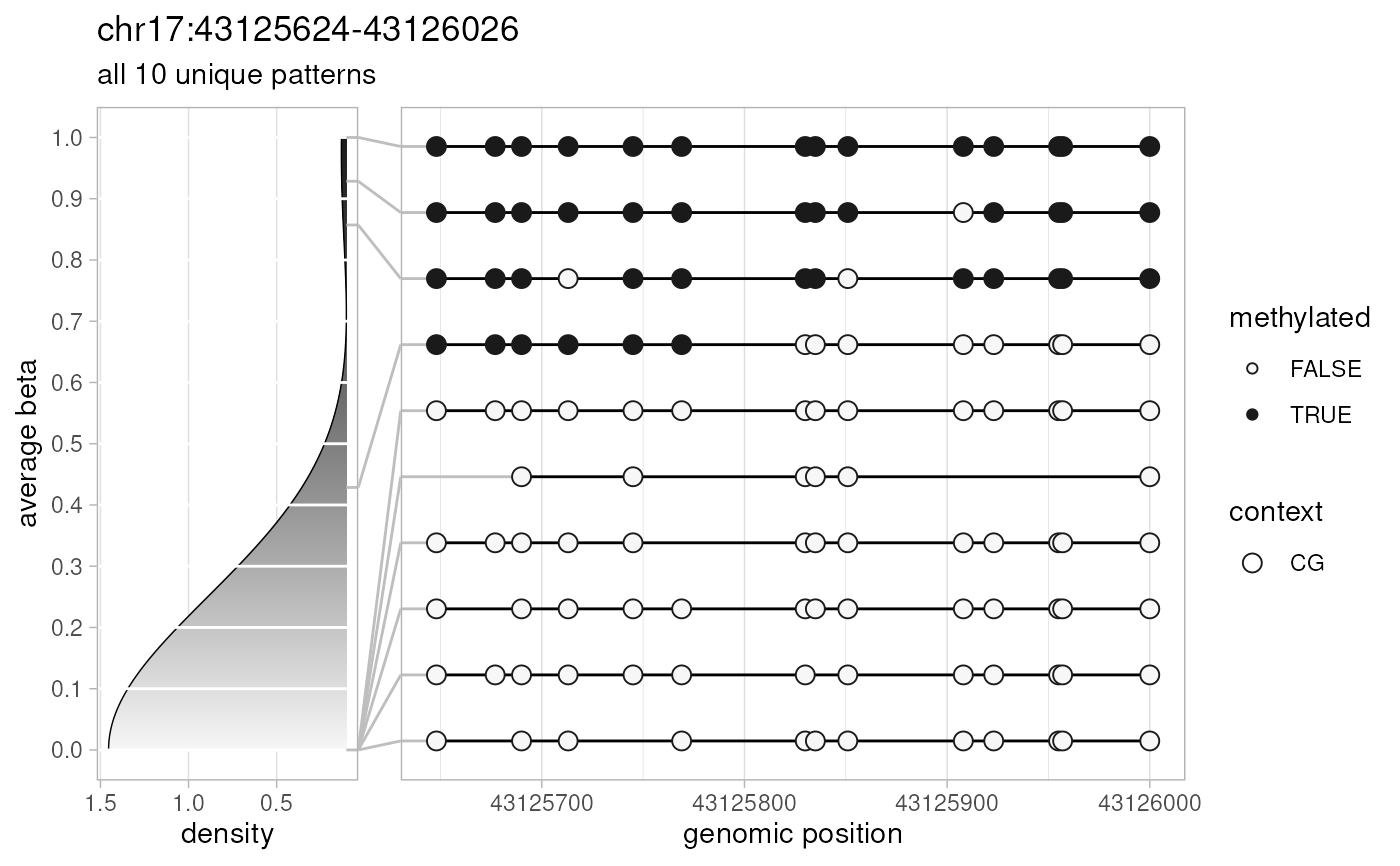
plotPatterns(
extractPatterns(bam=long.data, bed=long.bed),
npatterns.per.bin=Inf
)
#> Extracting methylation patterns
#> [0.017s]
#> 20 patterns supplied
#> 20 unique
#> 20 most frequent unique patterns were selected for plotting using 10 beta value bins:
#> [0,0.1) [0.1,0.2) [0.2,0.3) [0.3,0.4) [0.4,0.5) [0.5,0.6) [0.6,0.7) [0.7,0.8) [0.8,0.9) [0.9,1]
#> 16 1 0 0 0 0 0 0 1 2
# capture NGS
capture.bam <- system.file("extdata", "capture.bam",
package="epialleleR")
capture.bed <- system.file("extdata", "capture.bed",
package="epialleleR")
capture.report <- generateCaptureReport(bam=capture.bam, bed=capture.bed)
#> Reading BED file
#> [0.008s]
#> Checking BAM file:
#> short-read, paired-end, name-sorted alignment detected
#> Reading paired-end BAM file
#> [0.011s]
#> Filtering and thresholding reads
#> [0.001s]
#> Preparing capture report
#> [0.017s]
# generateAmpliconReport and generateCaptureReport are just aliases
# of the generateBedReport
bed.report <- generateBedReport(bam=capture.bam, bed=capture.bed,
bed.type="capture")
#> Reading BED file
#> [0.008s]
#> Checking BAM file:
#> short-read, paired-end, name-sorted alignment detected
#> Reading paired-end BAM file
#> [0.011s]
#> Filtering and thresholding reads
#> [0.001s]
#> Preparing capture report
#> [0.016s]
identical(capture.report, bed.report)
#> [1] TRUE
# long-read data can be used if clipped to a narrow target area(s)
long.bam <- system.file("extdata", "longread.bam", package="epialleleR")
long.bed <- as("chr17:43124909-43125554", "GRanges")
long.data <- preprocessBam(
bam=long.bam, targets=long.bed, clip.to.targets=TRUE,
min.mapq=30, min.baseq=20, min.prob=178
)
#> Checking BAM file:
#> long-read, single-end, unsorted alignment detected
#> Reading single-end BAM file
#> [0.007s]
long.report <- generateBedReport(
bam=long.data, bed=long.bed, bed.type="capture", filter.reads=FALSE
)
#> Thresholding reads
#> [0.001s]
#> Preparing capture report
#> [0.013s]
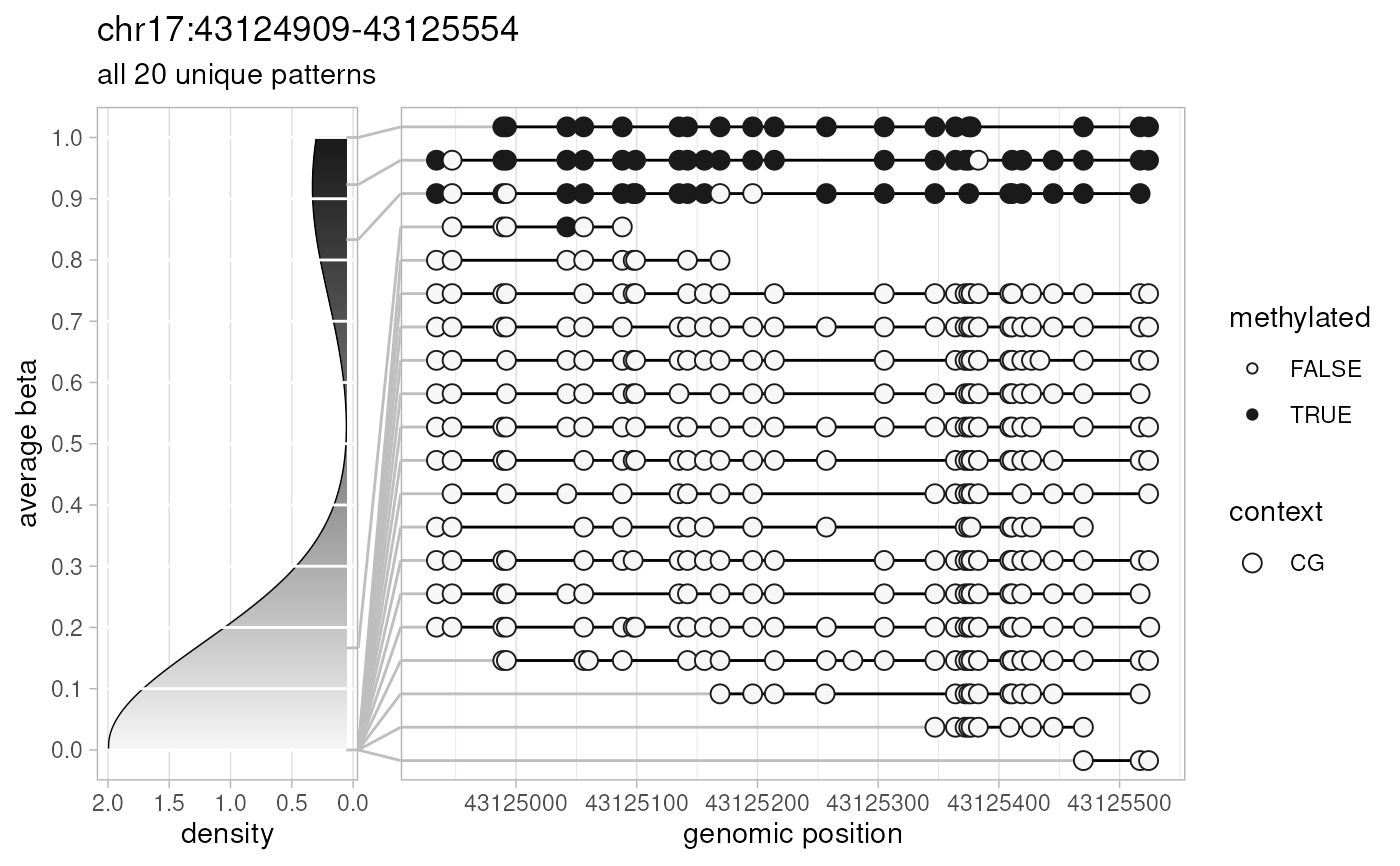
plotPatterns(
extractPatterns(bam=long.data, bed=long.bed),
npatterns.per.bin=Inf
)
#> Extracting methylation patterns
#> [0.017s]
#> 20 patterns supplied
#> 20 unique
#> 20 most frequent unique patterns were selected for plotting using 10 beta value bins:
#> [0,0.1) [0.1,0.2) [0.2,0.3) [0.3,0.4) [0.4,0.5) [0.5,0.6) [0.6,0.7) [0.7,0.8) [0.8,0.9) [0.9,1]
#> 16 1 0 0 0 0 0 0 1 2
 # toy example from the description
temp.bam <- tempfile(fileext=".bam")
temp.bed <- as("chr1:1-100", "GRanges")
simulateBam(output.bam.file=temp.bam, rname="chr1", XG="CT",
seq=c("AGACGTTAGTAATAGTA", "AAACGTTGTAATAGTA",
"AGACGTTGTAACAGTA", "AAACGTTGTAATGTA"),
XM=c( "...Z..x+.h..x..h.", "...Z..z.h..x..h.",
"...Z..z.h..X..h.", "...Z..z.h..z.h."),
cigar=c("7M1I9M", "16M", "16M", "12M1D3M"))
#> Writing sample BAM
#> [0.003s]
#> [1] 4
# with read filtering
generateBedReport(bam=temp.bam, bed=temp.bed, min.context.sites=2)
#> Checking BAM file:
#> short-read, single-end, unsorted alignment detected
#> Reading single-end BAM file
#> [0.002s]
#> Filtering and thresholding reads
#> [0.000s]
#> Preparing amplicon report
#> [0.013s]
#> seqnames start end width strand nreads+ nreads- nfiltered VEF
#> <fctr> <int> <int> <int> <fctr> <int> <int> <int> <num>
#> 1: chr1 1 100 100 * 2 0 2 0.5
# without read filtering
generateBedReport(bam=temp.bam, bed=temp.bed, filter.reads=FALSE)
#> Checking BAM file:
#> short-read, single-end, unsorted alignment detected
#> Reading single-end BAM file
#> [0.002s]
#> Thresholding reads
#> [0.000s]
#> Preparing amplicon report
#> [0.013s]
#> seqnames start end width strand nreads+ nreads- nfiltered VEF
#> <fctr> <int> <int> <int> <fctr> <int> <int> <int> <num>
#> 1: chr1 1 100 100 * 4 0 NA 0.75
# patterns plotted
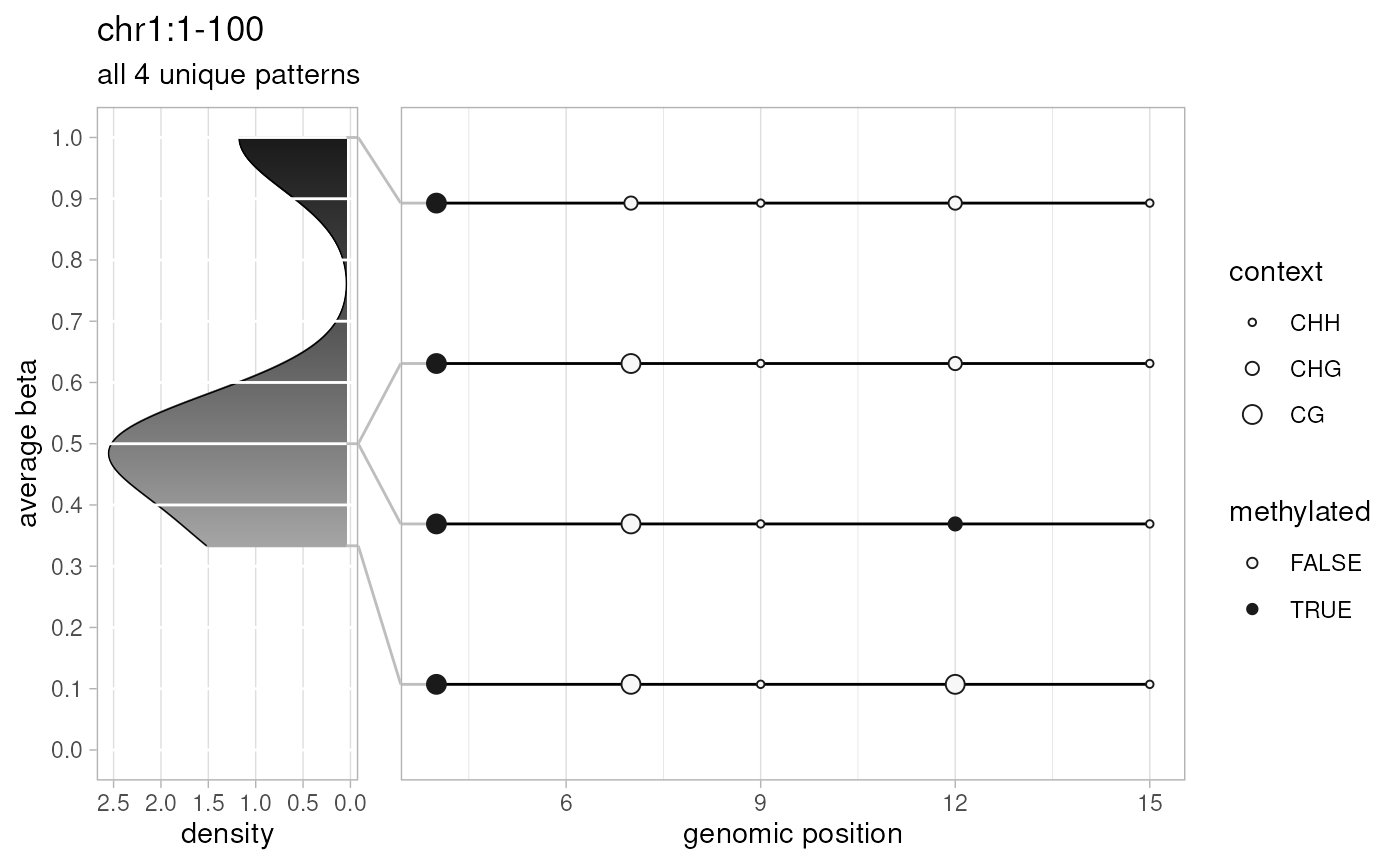
plotPatterns(
extractPatterns(bam=temp.bam, bed=temp.bed, extract.context="CX"),
plot.context="CX", npatterns.per.bin=Inf
)
#> Checking BAM file:
#> short-read, single-end, unsorted alignment detected
#> Reading single-end BAM file
#> [0.001s]
#> Extracting methylation patterns
#> [0.007s]
#> 4 patterns supplied
#> 4 unique
#> 4 most frequent unique patterns were selected for plotting using 10 beta value bins:
#> [0,0.1) [0.1,0.2) [0.2,0.3) [0.3,0.4) [0.4,0.5) [0.5,0.6) [0.6,0.7) [0.7,0.8) [0.8,0.9) [0.9,1]
#> 0 0 0 1 0 2 0 0 0 1
# toy example from the description
temp.bam <- tempfile(fileext=".bam")
temp.bed <- as("chr1:1-100", "GRanges")
simulateBam(output.bam.file=temp.bam, rname="chr1", XG="CT",
seq=c("AGACGTTAGTAATAGTA", "AAACGTTGTAATAGTA",
"AGACGTTGTAACAGTA", "AAACGTTGTAATGTA"),
XM=c( "...Z..x+.h..x..h.", "...Z..z.h..x..h.",
"...Z..z.h..X..h.", "...Z..z.h..z.h."),
cigar=c("7M1I9M", "16M", "16M", "12M1D3M"))
#> Writing sample BAM
#> [0.003s]
#> [1] 4
# with read filtering
generateBedReport(bam=temp.bam, bed=temp.bed, min.context.sites=2)
#> Checking BAM file:
#> short-read, single-end, unsorted alignment detected
#> Reading single-end BAM file
#> [0.002s]
#> Filtering and thresholding reads
#> [0.000s]
#> Preparing amplicon report
#> [0.013s]
#> seqnames start end width strand nreads+ nreads- nfiltered VEF
#> <fctr> <int> <int> <int> <fctr> <int> <int> <int> <num>
#> 1: chr1 1 100 100 * 2 0 2 0.5
# without read filtering
generateBedReport(bam=temp.bam, bed=temp.bed, filter.reads=FALSE)
#> Checking BAM file:
#> short-read, single-end, unsorted alignment detected
#> Reading single-end BAM file
#> [0.002s]
#> Thresholding reads
#> [0.000s]
#> Preparing amplicon report
#> [0.013s]
#> seqnames start end width strand nreads+ nreads- nfiltered VEF
#> <fctr> <int> <int> <int> <fctr> <int> <int> <int> <num>
#> 1: chr1 1 100 100 * 4 0 NA 0.75
# patterns plotted
plotPatterns(
extractPatterns(bam=temp.bam, bed=temp.bed, extract.context="CX"),
plot.context="CX", npatterns.per.bin=Inf
)
#> Checking BAM file:
#> short-read, single-end, unsorted alignment detected
#> Reading single-end BAM file
#> [0.001s]
#> Extracting methylation patterns
#> [0.007s]
#> 4 patterns supplied
#> 4 unique
#> 4 most frequent unique patterns were selected for plotting using 10 beta value bins:
#> [0,0.1) [0.1,0.2) [0.2,0.3) [0.3,0.4) [0.4,0.5) [0.5,0.6) [0.6,0.7) [0.7,0.8) [0.8,0.9) [0.9,1]
#> 0 0 0 1 0 2 0 0 0 1